I already announced about coming to MySQL Conference, but I didn’t realize preparing for it will take that much time. Last year I had just regular session about Wikipedia’s scaling and did feel that it is somewhat difficult to squeeze that much information into less than one hour. This year I opted in for 3h session (with short break in the middle), and instead of few slides with buzzwords on them I worked on workbook-like material to talk and discuss about.
Presentations are always easy, I have to admit I’ve made quite a lot of my slides an hour before actual talks. Now I realized that writing a workbook ends up to be a book, and books are not written in single day… Full disclosure: I looked at last year’s presentation files and blog posts for preparation of the talk, but still, things have changed, both in technology and in numbers. We have far more visitors (ha, >30kreq/s instead of 12kreq/s!), more content, slightly more servers and less troubles :-)
Today I’ve delivered the paper for printing (dead tree handouts for session attendees!), but there are many ideas already what to append or to extend, so this will end up being perpetual process of improving. Let’s hope tutorial attendees will bring their laptops for updated digital handouts.
Of course, the good part is that the real work will be over after first day and I’ll be able to enjoy other sessions & social activities. If only I survive the staff party..
Category: wikipedia
Bumping up the version
As Wikipedia is part of the Web 2.0 revolution, there has been already pressure to upgrade to Web 3.0. I personally believe we should take more drastic approach, and go directly for Web 4.0.
This Albert Einstein quote now rings in my head:
I know not with what weapons World War III will be fought, but World War IV will be fought with sticks and stones.
Wikimaniaaaaa!!!
It is somewhat too late to post about Wikimania, so I won’t keep it long. Finally my lightning talk bits are on internet. Please note, that the idea of presentation came just few minutes before giving it. Pity there’s no video recording.
Anyway, the trip was pretty cool. Besides meeting all usual suspects at Wikimania, the whole world of amazing academia (this time, in a good sense) was revealed by my hosts. MIT rocks (especially my place of stay, TEP). Boston was pretty nice too – I quite enjoyed long walks there.
The conference itself had technical stuff extracted into ‘Hacking days’, so I ended up at quite tense technical track rather than hacking sessions. It wasn’t that bad, so I could create ‘socializing track’ at the main conference, and just hang around without any real agenda.
We had there quite less of startup spirit, that was so vivid last year. The current theme is “What we’re doing ” instead of “What we’re going to do”. For some it is maturity, for me it is boring :) I hope that was wrong impression.
I’ll sure try going there next year too. Just to see the usual suspects.
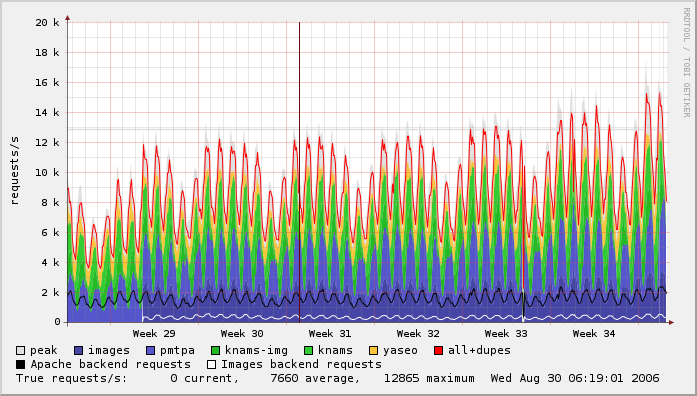
P.S. Wikipedia tremendous growth is back again.
my slides from users conference
Today I was pointed to my previous post on scaling, and I remembered, that I didn’t put my slides from MySQL Users conference online. Maybe those are not giving that much of detail, but still, can disclose some of facts from my talk: “Wikipedia: cheap and explosive scaling with LAMP”.
There’s also Brion‘s presentation at Google on wider aspects of project technology, with slides and video made public too.
teams without HQ
Fortune magazine has an article about banishing headquarters – MySQL virtual team. In same article Wikipedia is also given as an example. It is really nice to be in sharing and participation culture. And, ha, it’s 6’6″ :-)

{kind=link}