Most of database engines have to deal with underlying layers – operating systems, device drivers, firmware and physical devices, albeit different camps choose different methods.
In MySQL world people believe that InnoDB should be handling all the memory management and physical storage operations – maximized buffer pool space, adaptive/fuzzy flushing, crash recovery getting faster, etc. That can result in lots of efficiency wins, as managing everything with data problem in mind allows to tune for efficiency and performance.
Other storage systems (though I hear it from engineers on different types of problems too) like PostgreSQL or MongoDB consider OS to be much smarter and let it do caching or buffering. Which means that in top Postgres expert presentations you will hear much more about operating systems than in MySQL talks. This results in OS knowledge attrition in MySQL world (all you have to know is “use O_DIRECT, XFS and deadline scheduler”), yet Linux virtual memory behaviors and tuning are a constant issue where OS is allowed to cache or buffer.
This leads to very interesting behaviors – both PostgreSQL and MongoDB worlds have to deal with write starvation at checkpoint spikes – where no other operations can happen while data from dirty buffers is being written out to storage media. To help alleviate that instead of aiming to better managed I/O, they aim to keep less dirty pages in memory altogether. For example in Mongo world you will hear tuning recommendation to write out dirty pages once a second rather than once a minute (thus causing shorter stalls every second rather than system going dark every minute). Dirtying all the pages every second means that there is not much write merging going on and system is consuming expensive flash write cycles much faster than needed.
MySQL (and Flashcache) have demand driven checkpointing – pages are written out either if they are at the end of LRU and need to make space for fresh pages or too much log capacity is used and pages referred in oldest log events have to be synced. I prefer demand driven checkpointing much more as it means that system adapts to the workload and optimizes towards efficiency rather than performance workarounds.
So once I saw insert operations stalling for nearly a second in my tests on super-capable modern hardware (PCI-E flash, 144GB of RAM, etc), I started looking more at what can be done to eliminate such stalls. In order to be both efficient and not stall one has to do two things – reduce number of writes and prioritize important ones first. This is where the concept of “I/O scheduling” first comes to mind. As there’s lots of reliance on OS to do the right work, I looked at what exactly is being done.
From overall general perspective database workload on I/O stack looks like this:
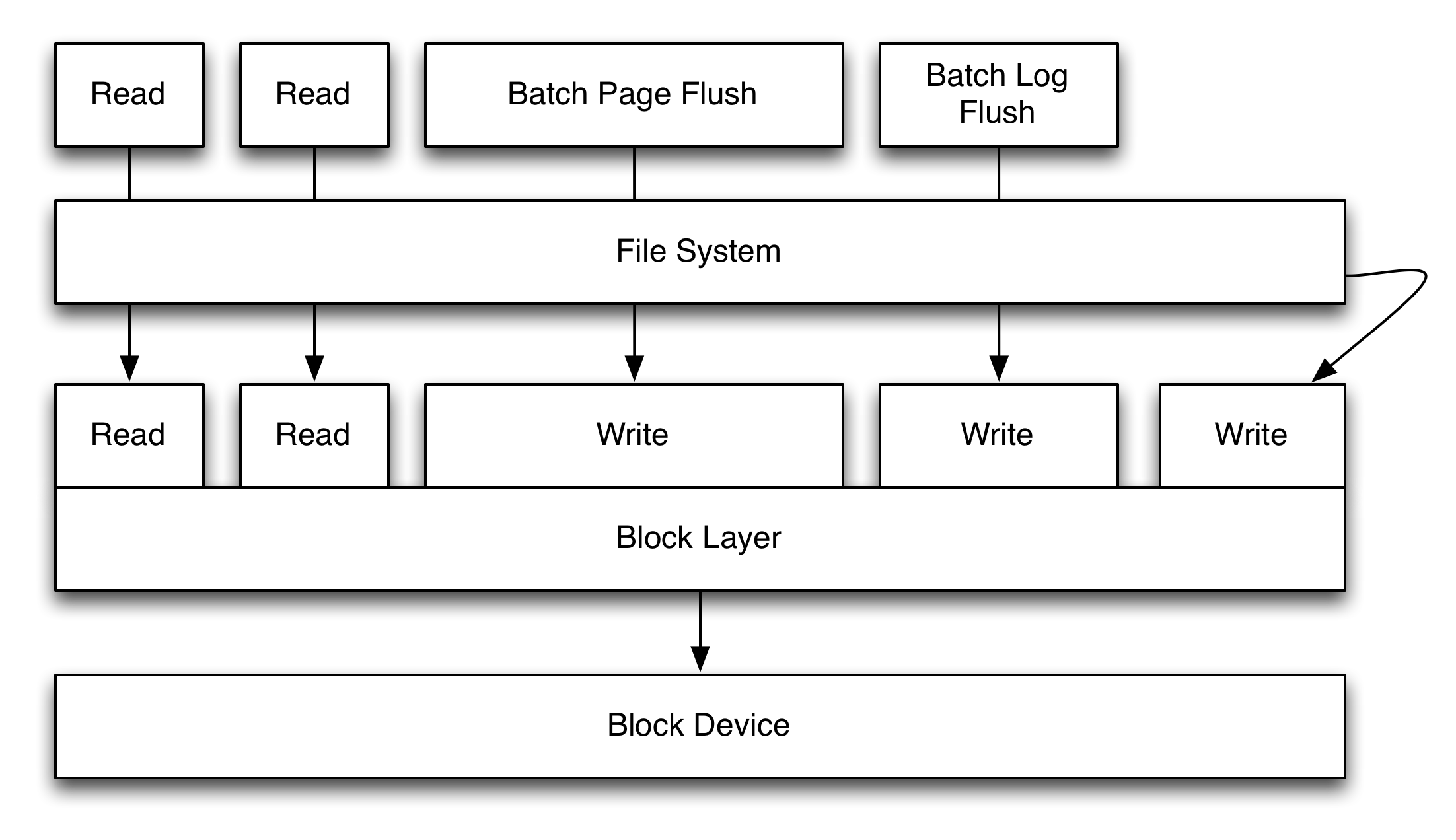
Alright, I probably could’ve done a better job at making a diagram, but my main observations here are that block layer has no idea what files you are talking to, only page reads and writes coming from various sources (threads/processes), all coming to single block device. There are some other interesting issues. For example a dirty page write is attributed not to the thread that modified the page, but the one that decided to flush it (so it is either some variant of pdflush, or userland thread calling fsync() or msync()).
So, to properly schedule things we need to inform operating system better about our intentions. The standard in database world is deadline scheduler, which separates reads and writes into separate queues and thats about it – it does not try to distinguish different types of writes coming from different sources. CFQ is much more complicated and allows to put different threads into different classes (realtime, best effort or idle) and priorities. Unfortunately, even if I attribute workloads correctly with I/O scheduling properties I hit another issue:

My two threads, one that has to get through ASAP in order not to stall system operations is actually stalling not because it cannot write its data soon enough, but because shared resource (file system journal) is being written (and delayed by scheduler) by idle or best-effort workloads.
There are two ways to deal with this, one is instructing file system to behave nicely and write its own journal with realtime scheduling, as otherwise it will stall other parts, or much simpler one – put transaction journal onto a separate file system (I can hear millions of “I told you so” voices, all forgetting that e.g. MongoDB does not even have configuration option where to put the journal and you have to hack your way around with symbolic links).
Obviously putting on completely independent device would also make sure that I/O scheduling is a non-issue too, but having multiple independent devices costs money, so we will have to still think about how to schedule things properly.
One would think that CFQ suddenly should be much more appealing as it allows to specify workload properties but the way it behaves is not exactly predictable. What one needs is much more straightforward rule set – don’t starve logs, don’t starve reads, allow other stuff to be drained eventually.
Technically, some of scheduling decisions can be simply be made by logical block addresses that get accessed (e.g. file system journal or DBMS transaction log) – and not by which thread is doing it – but interfaces to do that now are nonexistent.
There has been some interesting IO scheduler development at Taobao – they created FusionIO-oriented cgroups capable “tiny parallel proportion scheduler” for their MySQL workloads, that makes lots of sense in multi-tenant environments, but doesn’t yet address the problem of I/O starvation within same process that MongoDB has.
Currently if one wants to run Mongo or PG with perfect p99 (or pmax) behaviors, CFQ does not fully provide decent guarantees even with separate filesystems, and deadline is too limited in its scope. There should be more innovation in how user-land / file system / block layer cooperation should look like, rather than assuming that throwing hardware at the problem (or ignoring bad quality) is good enough.
That may be useful in InnoDB world some day too – I have seen issues where asynchronous batch write or read-ahead IO coming from many threads had capabilities to starve other workloads.
I tried some easy way out in some of the cases – currently MongoDB flushes one file at a time sequentially by calling msync() – which means up to 2GB flushes with default configuration or 512MB with “smallfiles” option. What one needs is much more predictable behavior, such as “flush 10MB at a time, wait for that to complete”. As it is not exactly tracked internally which pages are dirty and which are not, there is no way to provide that kind of throttling with current OS interfaces.
Though MongoDB already uses mincore() system call to check whether a page is cached in memory, there is no way yet to find out whether page is actually dirty (there have been LKML threads about providing that information). If there was an easy interface to get maps of dirty data from OS, database software would be able to schedule less aggressive writes without relying upon perfect I/O scheduler behavior.
P.S. Yes, I just blogged about MongoDB performance, albeit Mark Callaghan has been doing it for a while.
